WTSFest Philly is back on October 1st!
WTSFest Philly is back on October 1st!

Author: Ebere Jonathan
Last updated: 16/08/2023

Duplicate content is when the same, or very similar content is accessible via multiple URLs. These duplicate pages are inadvertently created in a number of ways - for example, having both HTTP and HTTPS versions of page; www, and non-www, page versions; UTM parameters; pagination series; and more.
Duplicate pages can cause problems because search engines often struggle to determine which version of the page ought to be indexed and shown to users in the SERPs.
How do we navigate these challenges and signal to search engines which pages to prioritize?
One technique we’ve relied on over the years for this purpose is canonicalization.

Image of duplicate dog content
Duplicate content is when the same (or very similar content) is accessible via more than one indexable URL. Below you’ll find a list of common issues which cause these duplicate pages to be created:
1. Alternate versions of a website: Having your site accessible in:
2. The same content is accessible via multiple URLs: These often result from filtering and sorting particularly on e-commerce sites. For example, when: https://www.example.com/dog-products/red-harness/ and https://www.example.com/category-dog/red-harness/ both display the same content.
3. UTM URLs: These are URLs with tracking codes or session IDs appended. For example: https://www.example.com/pages/?KW=ragnar&PK
4. Pagination: These are pages with same or very similar content across the pagination series. For example: https://www.example.com/ and https://www.example.com/?page=2
5. International Pages: URLs created to target different locations. For example: https://en-us.example.com/ and https://en-gb.example.com
6. Syndicated Content: Publishing content on other websites could lead to duplication if not managed properly.
On many websites, duplicate versions of a single web page may exist, and be indexable. In the context of SEO, canonicalization is the process of signaling your preferred version of the page - i.e. the one that you want search engines to show to users.
If you’re seeing different page versions ranking better than your desired page, implementing the canonical link element will help resolve the situation.
The canonical link element, or the canonical tag, is a code snippet placed on the head section of an html page to indicate to googlebot your preferred version of the page.
Here’s what the code looks like on a website:

Search engines have the ability to detect and ignore duplicates, so why do we need to worry about this? Well, the simple answer here is one of control: sometimes the search engines get this right, but often they don’t!
Imagine you work on an e-commerce website that sells dog harnesses in various colors. Individual pages have been created for each color variant, resulting in 10 different URLs for dog harnesses. The problem is, when someone searches for "dog harness" or related queries, all 10 URLs are competing to appear for those queries in the search results.
I love to compare the concept of canonicalization to a scenario where you bring a large cake to a school with a group of children eagerly awaiting its arrival. As soon as they see you, they all rush towards the cake, trying to grab a piece. In the chaos, some portions of the cake fall off, some children end up with more cake than others, and unfortunately, some children don't get any cake at all.
Now, imagine you’ve appointed someone to handle the cake distribution. This person accepts the cake on behalf of the group and carefully ensures that each child receives a fair and equal portion. By organizing and distributing the cake in a controlled manner, the chaos and unfairness can be avoided.
In the context of your website, canonicalization plays a similar role. When you have duplicate pages, it can lead to confusion for the search engines: some pages might be ignored, others might be given more prominence, and some might not appear in the search results at all.
Canonicalization steps in to bring order to this situation. It ensures that any duplicate pages are properly identified, and guides search engines to recognize and display a single preferred page in the search results. By designating the preferred page through canonical tags, you establish clarity and provide search engines with clear guidance on which version of the content to prioritize.
When Google encounters multiple pages that seem similar during indexing, it chooses a page as the canonical . But how does Google determine this? According to Google documentation these are some of factors they consider:
Mobile over Desktop: With the mobile-first indexing approach, Google will choose to prioritize the mobile version of a page on search result over the desktop version, because more users access the web with mobile devices and Google aims to provide the best user experience on mobile.
HTTPS over HTTP: Google prefers to serve secure pages (HTTPS) over non-secure pages (HTTP) although there are exceptions which you can read about here.
“Clean” URLs over URLs with Parameters: Google favors shorter, cleaner URLs as it considers them more user-friendly. For example, https://www.womenintechseo.com/mentorship/ will get a higher preference over https://www.womenintechseo.com/blog/mentorship?2023=july/
Pages over PDFs and other file formats: Google will typically choose webpages as the canonical version as they are more accessible to users than PDFs or other file formats.
Language: If you have created pages to target multiple languages and locations, Google may consider the query language as canonical, meaning if a user performs a search in French, Google will choose your French page as the canonical.
Overall Page Signals; Google evaluates various page signals, including user experience (UX), expertise, authoritativeness, trustworthiness (EEAT), and language relevance. Pages that exhibit strong signals in these areas are more likely to be chosen as the canonical version.
Optimizing our preferred pages to align with Google's preferences will increase the likelihood that our desired canonical pages are chosen.
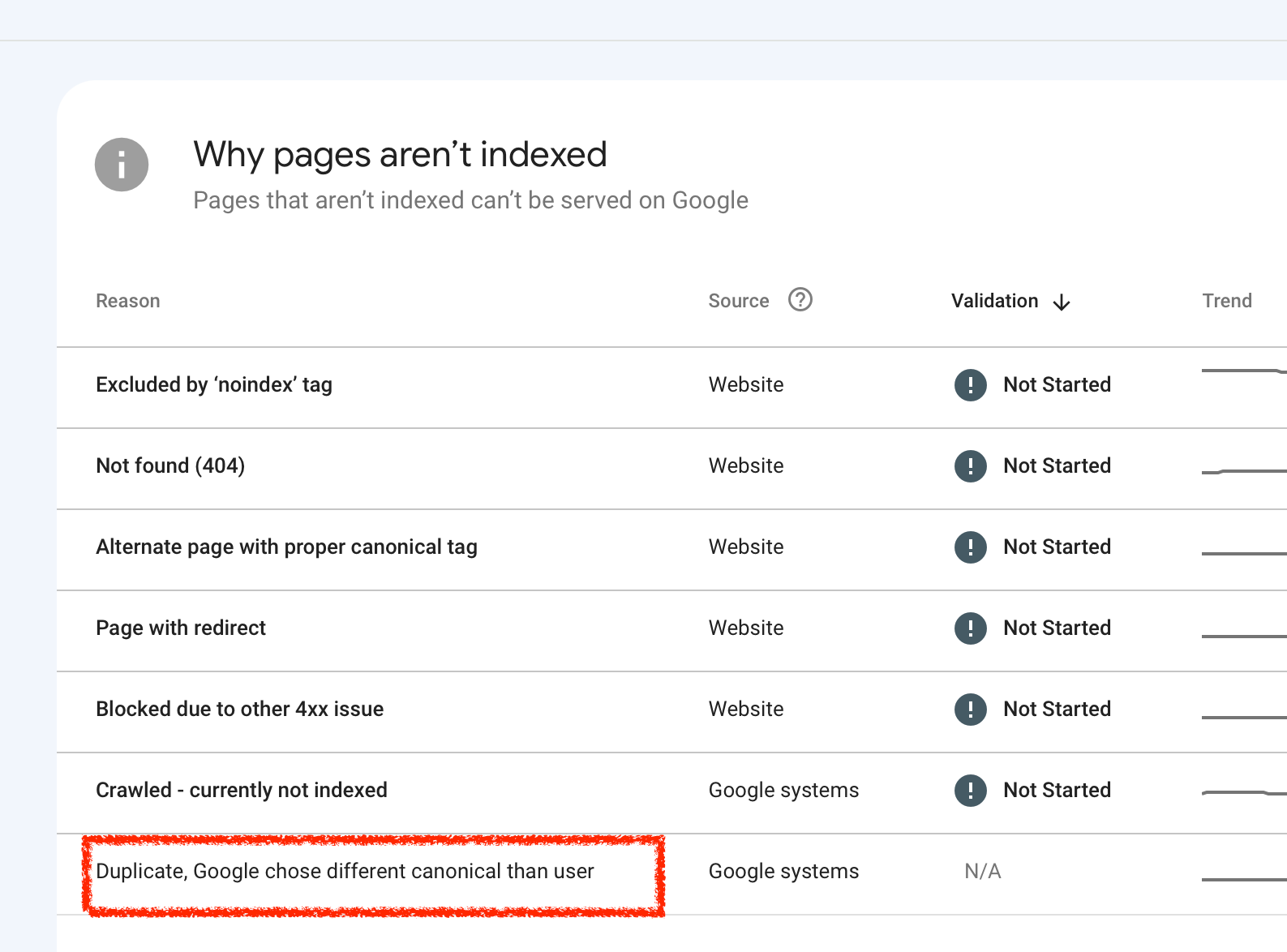
The canonical element is the easiest way to tell Google that there is a version of this page that you’d like to be indexed. Including <link rel=”canonical”href=https://www.example.com/> in the HTML header of a page acts as a signal, but because the canonical tag is a hint, not a directive, sometimes, (as illustrated in the screenshot below), it is ignored:
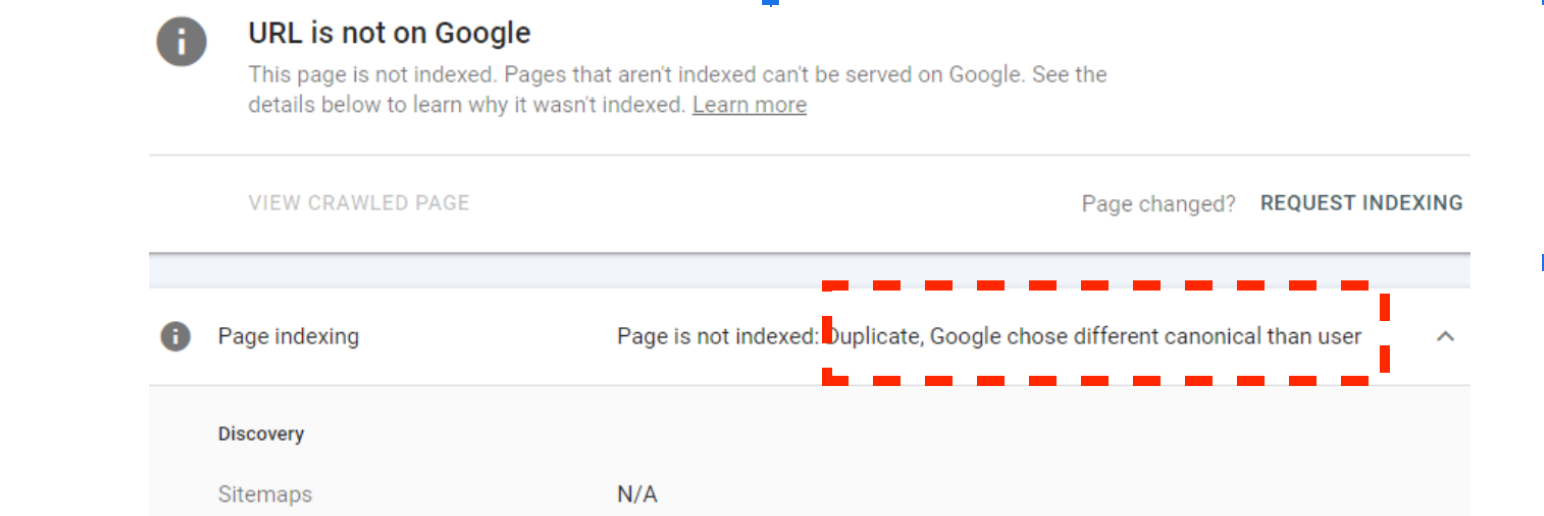
Screenshot of GSC, Canonical Report, June 2023
How do you resolve issues like this? Follow the steps below to send a stronger signal to Google:
All these canonicalization factors come together to tell Google which URL you prefer and help demonstrate that the canonical link elements on your pages are deliberate and should be honored.
How do you know if your site has canonicalization issues?
Follow the steps below:
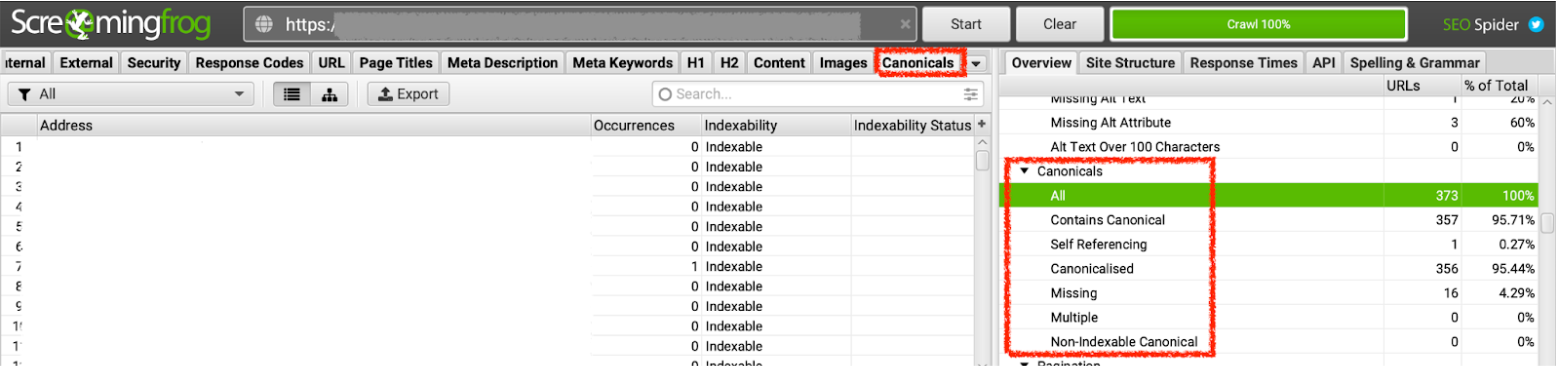
Screenshot of Screaming Frog Canonical Report, June 2022
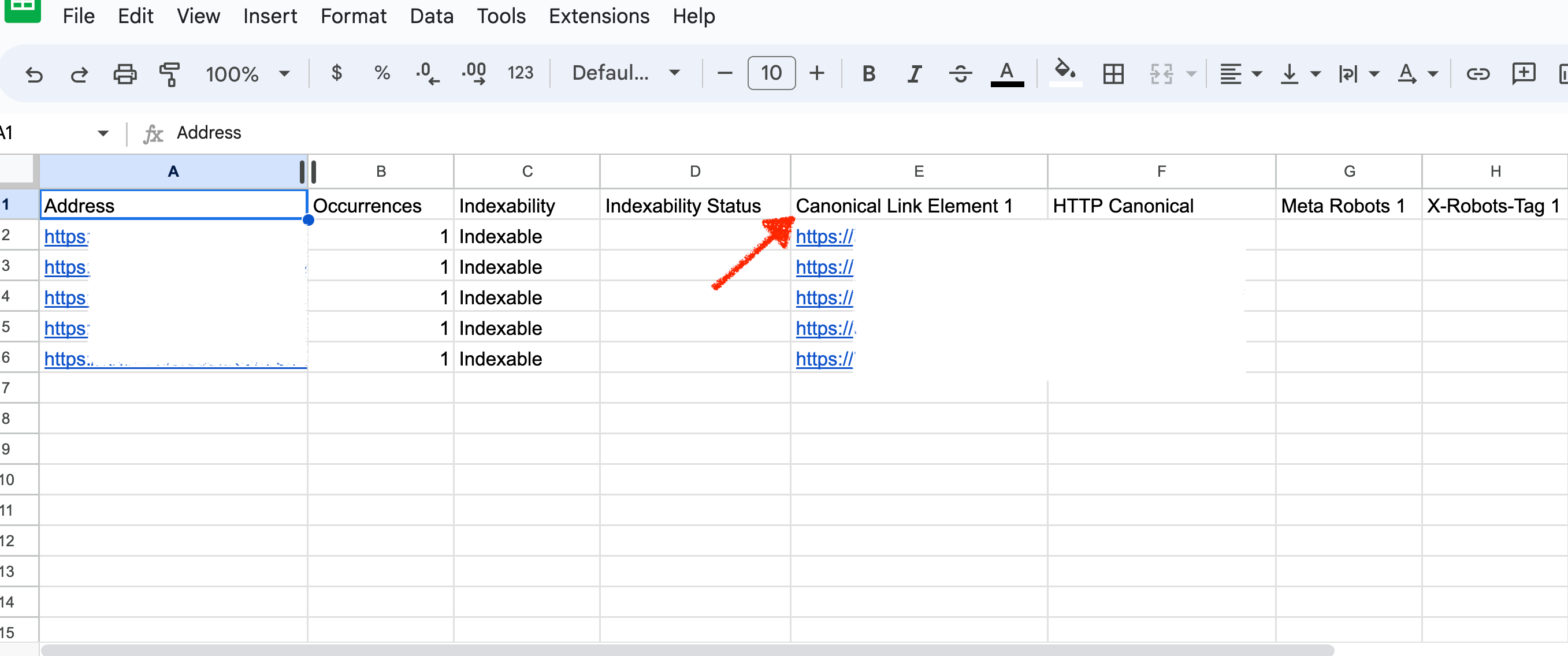
Screenshot of Google Sheet Canonical Data, June 2022
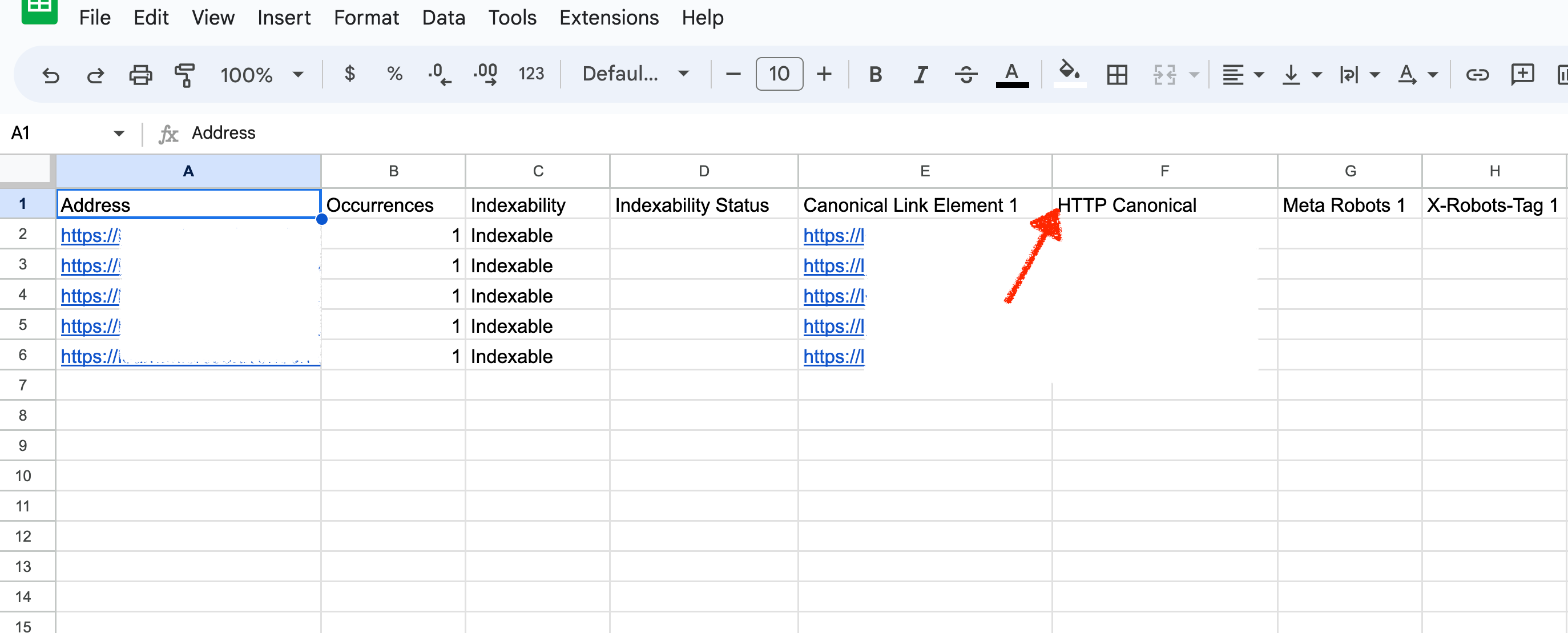
Screenshot of Google Sheet Canonical Data, June 2022
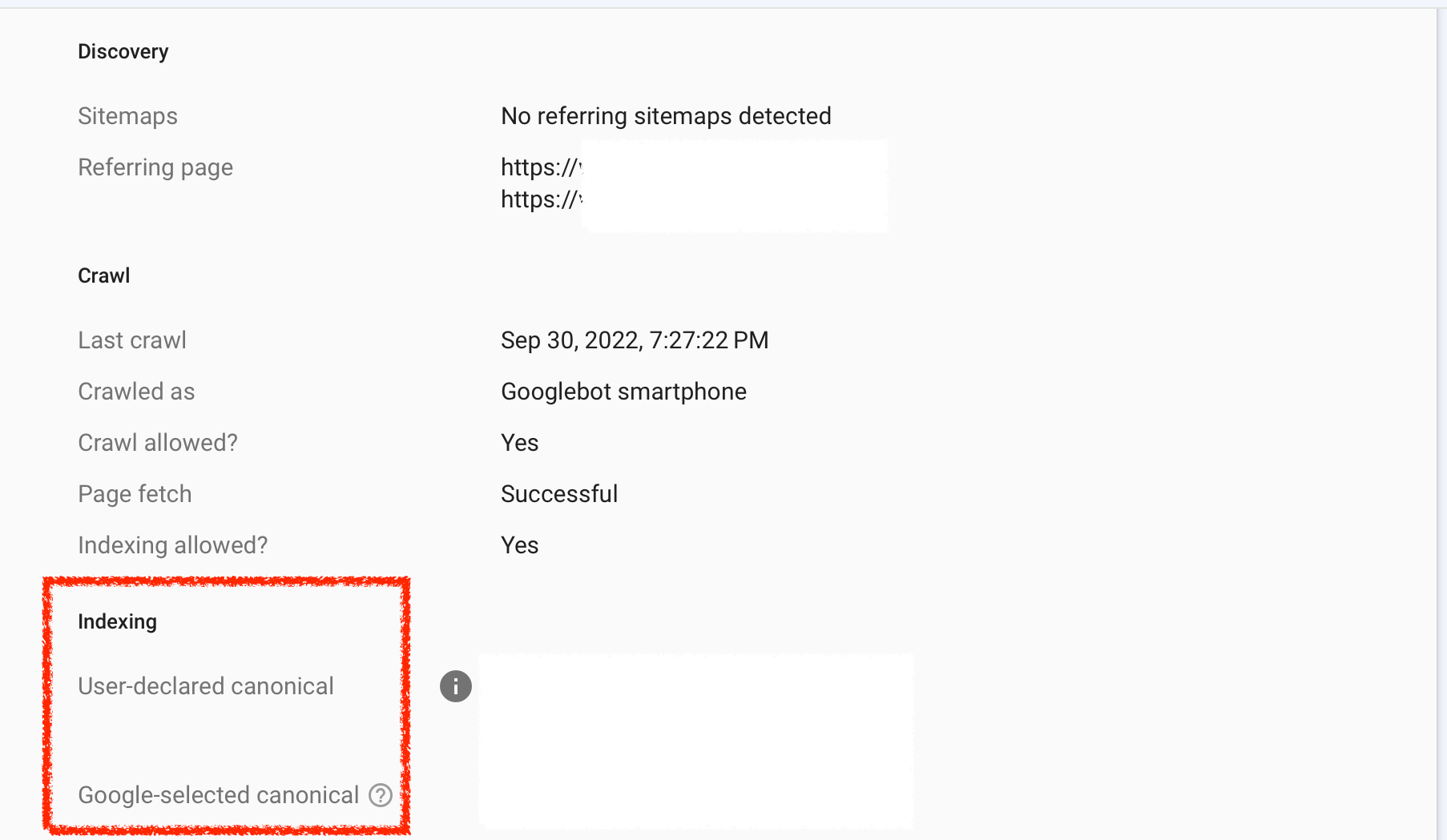
Screenshot of GSC, Page Indexing Report, June 2022
Screenshot of GSC URL Inspection Report, June,2022
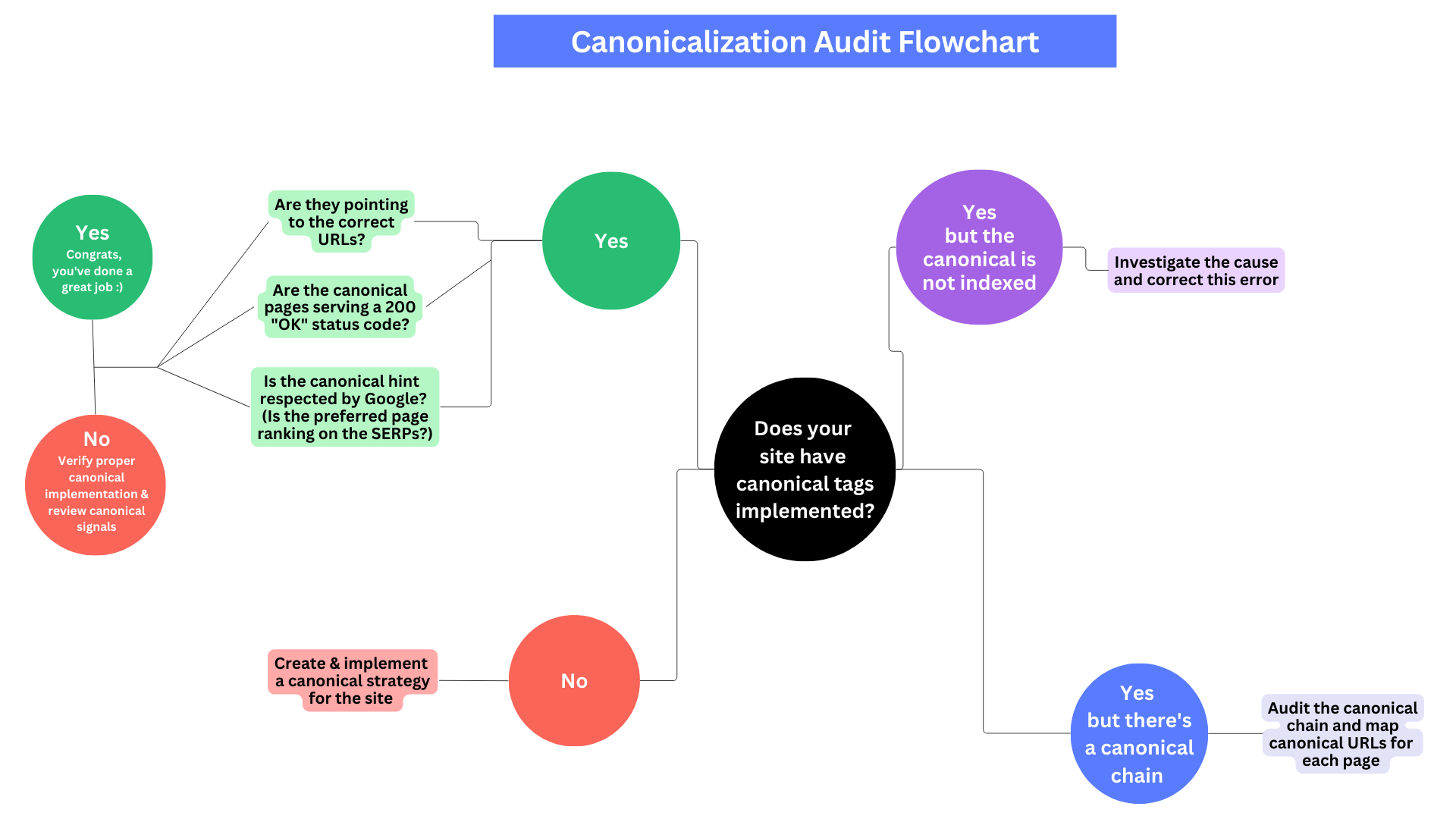
Image of a Canonicalization Audit Flowchart
You can implement rel=”canonical” on your site using one of these two methods:
Include a canonical link element on the header section of your duplicate HTML pages with the URL pointing to the preferred version. Here is an example:
<html>
<head>
<title>Red Dog Harnesses</title>
<link rel="canonical" href="https://example.com/dog-products/red-harness" />
<!-- other elements -->
</head>
<!-- rest of the HTML →
Use absolute paths when implementing the canonical tag, rather than relative paths. For example, use: https://www.dogstore/dog-harness/red-harness/ not dogstore/dog-harness/red-harness/.
While it's generally not advisable to implement a canonical link element in JavaScript, if you have limited options, you can do this. But be cautious here, incorrect implementation may lead to site-wide canonical issues and unexpected results. If you choose to implement JavaScript-based canonicalization, follow this guide to ensure accurate implementation.
For documents like the PDFs, XLX, Word documents, images, or videos, you’ll need to implement the canonical or X-robot tag in the HTTP header rather than on your HTML page. This method requires access to your server configuration file. Here is an example:
HTTP/1.1 200 OK
Content-Length: 19
...
Link: <https://www.example.com/downloads/dog-names.pdf>; rel="canonical"
Canonical Chains
When a canonical tag points to a URL that has another canonical or redirect it creates a canonical chain. For example, if the “dog-harness” page is set as the canonical for the “red-harness” page, but the “dog-harness” page is redirected or has its own canonical pointing to the “dog-products” page it creates a conflicting signal and Google may abandon the hint altogether. This issue can occur due to improper injection of canonical with JS or errors in CMS plugins. Periodic canonical audits can help you catch and fix issues like this.
Placing the canonical tag in the body
Information about your page including canonical tags, should be added to the head section. Canonical tags in the body section will be ignored by Google. Checking where your canonical tags appear will help you identify if any elements such as iframes or unclosed tags have accidentally pushed the canonical link element into the body section of your pages.
Canonicalizing paginated pages
Many people elect to canonicalize paginated pages in order to avoid competition, as they often have similar content. However, doing so can hinder the discovery and indexing of the individual pages which are linked to from the pagination series. If this is a concern, it’s advisable to implement self-referencing canonical tags on paginated pages instead.
Sending conflicting canonical signals
If you set a canonical tag for a particular page, but then include include a different variant of that page in the sitemap, or link internally to this variant, it sends a mixed signal and could cause search engines to think: “Oh, they’re definitely confused, I’ll ignore the canonical tag and select the canonical version myself”. Maintaining consistency emphasizes your intention to the search engines.
Canonicalizing cross-domain or syndicate content: Previously this was considered good practice. however, Google have updated their documentation stating that: “The canonical link element is not recommended for those who wish to avoid duplication by syndication partners, because the pages are often very different”. The most effective solution according to the updated Google documentation is for partners to block indexing of syndicated content.
Can I use 301 redirects in place of canonical tags?
While redirects and canonical tags are both canonicalization signals, they serve different purposes and shouldn’t be used interchangeably. When you want to permanently merge two pages into one and make them accessible via a single URL, a 301 redirect is the appropriate choice. On the other hand, if you want to consolidate similar pages but keep them individually accessible while indicating a preferred version for search results, using the rel=”canonical” tag is recommended. Ultimately, if having similar content on multiple URLs serves no purpose, a 301 redirect should be used. Analyze and implement what is best for your users in each case.
Do canonicalized pages get de-indexed?
If Google obeys the canonical hint, it will consolidate the pages including things like link equity, and index the canonical page specified. However, this doesn’t mean that the canonicalized page isn’t indexable. The only way to ensure a page does not appear in the search results is to implement a no-index tag.
What’s the benefit of using the canonical tag with a hreflang annotation?
Hreflang helps signal to search engines which URL you want to show users in different locations or searching in different languages.
Imagine you have an “en-us” page for English speakers searching for dog-products in the USA, and an “en-gb” page for English speakers in the UK. Here, hreflang helps the search engines identify which version to show to which user; while the canonical tag shows which version to rank regardless of language and location.
Can I use the canonical tag and meta robots tag together?
While commenting on a canonical vs no-indexing question during Google SEO office-hours hangout, Google’s John Muller said:
“…you can also do both of them. [And it’s something…] if external links, for example, are pointing at this page then having both of them there kind of helps us to figure out well, you don’t want this page indexed but you also specified another one. So maybe some of the signals we can just forward along.”
However, it might be preferable not to risk sending conflicting signals to Google. You can watch the full video of John Muller’s response here.
What do I do if Google ignores my preferred canonical version?
Audit the page as outlined earlier in this article in order to identify any possible errors that could be causing Google to ignore the hint, and consider implementing one or more of the tips above to help send a stronger signal.

Ebere Jonathan - Freelance Technical SEO Specialist
Ebere is a Freelance Technical SEO Specialist who enjoys spending time finding technical opportunities that improve website rankings and traffic. She has worked agency-side and audited websites in different sectors including e-commerce, healthcare and travel.
We pay our authors, speakers & team to bring you helpful content like this.
We aim to always keep our content and community free and accessible.
If you've found value in WTS, please consider supporting us through our Buy Me a Coffee initiative.
