🌲 WTSFest Portland - May 7th 2026 | 🥨 WTSFest Philadelphia - October 1st 2026
🌲 WTSFest Portland - May 7th 2026 | 🥨 WTSFest Philadelphia - October 1st 2026

Author: Dawn Anderson
Last updated: 02/03/2026

The SEO industry has long had a reputation for circulating myths, or alternative interpretations around how search works, partly because our field sits at an awkward intersection between marketing and computing. Unlike paid search, or pure computer science and engineering, much of SEO knowledge is subjective, based on imperfect experimentation and educated guessing to varying degrees, with wide ranges of experience and perspectives held between debaters.
Our industry suffers from an absence of definitive answers, plus a largely stakeholder-driven desire for simple levers to ‘move the needle’.
“It depends” is our ‘go-to’ industry slogan after all, where nuance and ambiguity rule.
Unsurprisingly, as Large Language Models (LLMs) and their use as generative tools have grown in search environments, the potential for misinformation has been further exacerbated. The floodgates have opened for more SEO myths to join the ranks of the longstanding cyclical debates around subjects such as ‘subdomain v subfolder’, ‘301 v 302 redirects’, and ‘clicks impact rankings’.

Pinocchio attempts to explain SEO and AI Search to Jiminy Cricket.
We are at an exciting technological search intersection, but the pace of change leaves a temporary knowledge vacuum. Additional concepts are entering our space from Information Retrieval (IR), Natural Language Processing (NLP), Machine Learning (ML) and Computer Science (CS) domains.
As a result, we face a ‘misinformation super-highway’ inflated by new myths around Generative AI, and Generative IR, along with all the other myths and cyclical discussions. Misinterpretations and manipulations of out-of-domain terminology leave us open to greater confusion during arguably our most challenging period.
Whilst there are many possible reasons SEO myths grow, patent misinterpretation and hyperbole certainly contribute.
Search patent law is complex, because its interpretation requires not only legal understanding, but deep search and IR understanding – a rare and unique skill combination the much loved, late Bill Slawski held to perfection. Bill provided us with almost unequivocal and extensive patent interpretations given his multi-decade knowledge of search, and previous career and formal qualifications as a lawyer.
The general belief that ‘patents mean production’ adds to the confusion, because in the majority of cases patents never reach production. Patents are produced for many reasons, including strategic asset defense. These ‘defensive patents’ are registered to block competitors from implementing alternative solutions, or used as legal leverage in competitive industries. Plus, it’s not just the patent itself which needs to be interpreted correctly, but also the accompanying references section which often cites many academic papers.
Academic papers published by search, IR and NLP researchers are all too easy to misunderstand when taken out of context. Not only is the language throughout these papers dense, dry, and interspersed with mathematical equations; they reference and cite numerous other academic papers, which also need to be read in order to fully understand the historical research each paper seeks to build upon.
I suspect that a hint of the sycophantic echo chamber and herd mentality also have their part to play in the spreading of misinformation around AI SEO. The rise of GEO, AEO, (EIEIO anyone?) has seen a corresponding rise in folks seeking to maximise this new opportunity and reposition themselves as leading the way.

Old McGoogle had a farm, EIEIO.
We’re all profoundly aware SEO is evolving (and the opportunity is growing), but some of these approaches to sharing information without rigour, muddy the waters and risk leading the reputation of the SEO industry further down the perceived path of ‘snakeoil salesperson’ as we move into these next stages of search in an AI era.
We are all learning about new changes in our industry as quickly as we can, but this avalanche of new developments potentially brings with it a tendency amongst us to not want to admit when we don’t know the answers to many of the questions being asked of us.
Grasping at out of context soundbites from academic papers, unreplicable experiments (to be fair, most research is unreplicable), randomly isolated Colab scripts performing a single task or tactic, and other SEO myths lead to a probabilistic filling in of gaps, rather like the hallucinatory nature of the LLMs whose output we all bemoan as nonsense.
So, let us look at some examples of the out-of-category, or new terminology interpretations which are sowing uncertainty.
Recent emerging SEO terminology seeks to identify new levers, but they are arguably based on category errors confusing how Generative AI, Generative IR and classic IR systems are engineered internally with how search engines rank and surface content externally. Two such possible cases of this are chunking and information gain.
Amongst the most prevalent of the SEO levers which are currently circulating proposes it is the job of SEOs to create ‘chunks’ (small sections of content) for LLM bots to consume in the hopes of increasing visibility in both AI Overviews / AI Mode, and LLMs.
Whilst it’s certainly true that chunking is still currently necessary in the preprocessing of content in NLP due to the size limitations of context windows, it’s important to note that chunking is not a metric for evaluation or ranking.
Chunking looks to ensure no loss of information and enables technical processes like vector embedding and Retrieval Augmented Generation (RAG) or other NLP processes as a mechanism for knowledge retrieval. Any number of Python scripts and a Google Colab or similar can be used to run a chunking script over text and it's certainly fun to experiment with chunk simulation to understand what might be happening in the preprocessing stages. There are lots of examples across the likes of Kaggle and Hugging Face and a number of Python data analysts share these readily as well.
It’s arguably not the job of SEOs to try to chunk the content on the front end. Attempting to chunk pulls away from natural, human-focused text with little long term value beyond showing others in the SEO space we can chunk with the best of them, and perhaps some temporary impact like many AI spray and pray techniques. You do you, but in my opinion this is a short term tactic, and the longer term benefits are debatable.
Here are some reasons why:
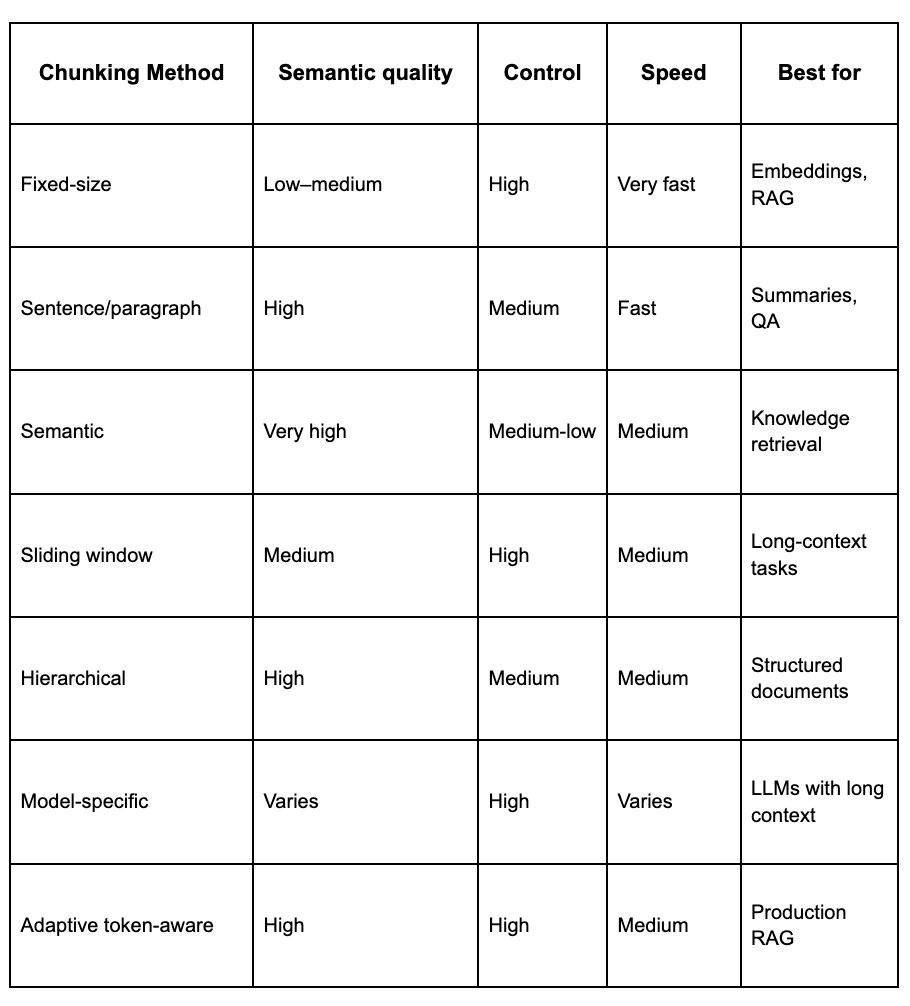
Firstly, there are multiple types of chunking, (and undoubtedly hybrid techniques too), each of which serve different computational needs and NLP or ML use cases, whether RAG or some other retrieval or contextual understanding task.
The simplest fixed-size type of chunking continues to be the predominant industry standard due to its low cost and speed, but its limitations are based upon either characters, words, tokens, or cutoff points with pre-determined boundaries and no contextual value.
In contrast, sentence-based, paragraph and document based chunking splits text into larger pieces, with more context, but higher computational costs. More recent advanced and expensive (performance) chunking methodologies utilise semantic methods, or recursive combinations of semantic, hierarchical (parent-child or tree-like), and fall-back techniques. Other chunking techniques include sliding-window, topic-based, modality-specific, agentic and AI-driven dynamic. Some of these will be rarely used in production at scale because they are simply too expensive.
But… Which chunking methods do Google use in Gemini whose multi-step reasoning powers AI Overviews? Which ones do OpenAI use to power ChatGPT?
The answer is of course: we DON’T know.
Like most aspects of modern NLP and IR the methods used will vary according to the task. It’s the same with query matching (sometimes it's a simple keyword match, sometimes there is a call for more ML driven approaches) – it depends.
So how can we replicate what good looks like if we don’t even know which chunking methodologies are implemented? And, are we trying to ‘help’ by breaking up our content into bite-sized chunks, or inadvertently ruining user experience with disjointed content?
Perhaps most importantly, chunking is not ‘future-proof’ – optimising for the current limitations of LLMs is pointless. As LLMs and search engines improve their own chunking approaches over time, what looks like natural human-focused content will continue to emerge, leaving artificially SEO-ed and chunked content standing out like a manipulated sore thumb, vulnerable to negative impacts by future algorithmic updates.
Indeed, during a very recent Search off the Record podcast, Google’s Danny Sullivan confirmed Google do not want SEOs to chop content into bite-sized pieces (he’d already asked search engineers internally about this subject), and claimed it’s something that won’t work for search engines, and even if it works for the time being for LLMs, it won’t in the future. Danny went on to reiterate that short-term hacks will not work in the longer term as search engines seek to reward natural content created for humans rather than bot consumption.
Whilst it’s lovely to be able to tinker with these approaches ourselves so we can show we can ‘chunk’ with the best of them (I jest), and grow our knowledge, in the longer term its value as an actionable SEO lever is limited. Let’s not let chunking for machines, and AI slop become the Panda-esque version of ‘article spinning’ of the latest SEO cohort.
There is a significant difference between chunking and clear semantic structuring and that also appears to be part of the confusion. Articles suggest chunking but then provide examples which are merely semantically structured content, a concept that is decades old.
Semantic headings have always carried additional weight in information retrieval papers of old with the descending importance around H1-H6 clearly documented. Incidentally, this is a method very rarely utilised to its full extent by website owners nowadays (you should change that).
Semantic structuring has been around for decades and can be loosely defined in its use as a clear waterfall hierarchy within a document on the web or other knowledge repository, providing guidance as to the descending importance of content sections (not chunks) rather like the inverted pyramid style of journalism.
Both semantic structuring and inverted pyramid style content do have value, but they are not chunking.
Wikipedia has been structuring content perfectly like this for decades via a structured, linked and semi-structured data system which uses semantic headings, tables, ordered and unordered lists. This type of structuring in content adds value for humans, search engines, and bots seeking to disambiguate and understand the sections of a document.
Tabular data is also structured data, since it is in reality the type of content found in relational databases, yet it's rarely referred to as a type of structured data.
It’s no coincidence either that unordered and ordered lists appear a lot in the likes of featured snippets due to their easily extractable and unambiguous nature when compared to the messiness of unstructured text.
Remember passage-indexing? That was a hot topic back in 2020/2021 when Google announced they would begin to seek to understand parts of a page in isolation rather than simply looking at a page as a whole. At the time, the examples provided by Google and in various webinars were often centred around a fictitious blog post mostly about dogs with a small section in the page about cats, or vice versa.
Google now wanted to be able to rank the section about cats for cat related queries independently of the parts about dogs for dog related queries, particularly in the absence of unstructured semantic content (i.e. for content produced naturally by SEO unaware content creators). Whilst this is search specific it’s highly likely there are some crossovers between these technologies and chunking on the search engine or GIR preprocessing side of search, given the iterative and evolutionary nature of these technologies, and the connections in literature between passage indexing and BERT based systems.
This is yet another possible reason why SEOs do not need to get too involved in the chopping up of content into tiny pieces – search bots and LLM bots are likely ahead of the game already; are always working to improve even further; and want to see a picture of ‘what natural looks like’ as a part of their overall approach.
Another new(ish) and popular term picking up traction which is potentially misinterpreted and predominantly from another domain is that of ‘information gain’.
The SEO version of this terminology is largely derived from the contents of a single Google Patent: ‘Contextual estimation of link information gain’. It’s achieved widespread uptake in the SEO conversations of today as meaningful and actionable, but in truth it’s a vague and unmeasurable metric to strive for.
I already touched on the challenges of patent interpretation because of the combination of both legal terminology, academic and search understanding it requires. Whilst perspectives vary in the SEO community on what the Google patent means by ‘information gain’, the general consensus is that Google implies that if given a choice between two pieces of content, the piece which provides the most added value in terms of information will be considered the optimal choice to rank due to its ‘information gain’ (i.e. the value is higher in that piece compared with its competitor page).
It sounds like a simple enough concept to get your head around since the explained purpose seems to fit perfectly with the name on the tin.
This notion of ‘information gain’ is also aligned with the long-established concept of the Skyscraper Technique. The Skyscraper Technique is a well-known backlink building methodology, where the objective is to identify the content competitors have used to acquire strong backlinks with; then replicate and improve upon it (i.e. add another floor to the skyscraper), and subsequently replicate the backlinks.
As such, whilst ‘information gain’ seems like a new concept in the SEO space, it is not that different to other concepts out there, although the patent discovery seems to have added some validation to bunging another floor on the SEO value-add skyscraper.
The question is – what SEO would not naturally try to add value to a piece of content as part of their overall strategy?
It is amongst the bare essentials of the job. Identifying strong competitor content, looking at ways to improve upon that content to make it more relevant, more precise, and more valuable.

You were probably already doing that anyway
I suspect the vast majority of SEOs are already undertaking some kind of competitor analysis and implementing approaches like this, and had been doing so for many years before the Google ‘information gain’ patent was reported on.
Submit a query of ‘information gain’ into any search engine and you won’t find the dominant search results referring to the SEO-adopted version of the term, because information gain has much bigger meaning when you look into it from an algorithmic and machine learning perspective. The term is huge.
Information gain in the machine learning sense has, at its heart, the concept of entropy; a measure of the levels of uncertainty in information. It is originally derived from an academic paper with over 118,000 citations entitled: ‘A Mathematical Theory of Communication’ (Shannon, 1948). The paper’s author, Claude Shannon, nicknamed the Father of Information Theory, developed the mathematical framework of entropy as a key principle. Claude Shannon’s legacy as a mathematician and his work’s eventual contribution to the machine learning space was so profound that Anthropic named their well-known LLM, ‘Claude’ after him.
Ross Quinlan later adapted Shannon’s work for the machine learning era specifically by utilising ‘information gain’ as a splitter in decision trees, one of the most popular types of machine learning classifiers, or regressors for classification and regression (prediction) models respectively.
Search engines will undoubtedly be utilising information gain or entropy, day-to-day in decision trees (or in forests of decision trees called random forests) as classifiers or regressors but likely well beyond a single patent, because classification and regression models are bread and butter in AI and ML.
None of this is to say that ‘information gain’ in the Google patent does not have merit, but when we take the more well-known concept from machine learning, and understand that it is used to split data on decisions when classifying or predicting, it does provide further context as to how information gain may alternatively be used to understand the purity of a page to a topic or class, rather than understanding how much additional value content might add.
Purity of class or topical focus is the gain in itself and we already know from machine learning this is how decision tree classifiers work more widely to understand how pure a split of data is.
Other areas within search engines, and across GIR and GAI surfaces where information gain may be used could include: determining the canonical version of duplicate, or near duplicate pages (likely what the information gain patent itself refers to); for deciding which pages to add to a crawl schedule based on the split of relevance and/or precision to a topic (particularly in focused crawling which is around topics specifically); or for deciding the depth to allow in traversal, or the minimum levels of value a decision tree leaf should provide before further splitting is undertaken when resources are limited.
Google’s search team has not confirmed that they use information gain in the ways in which the patent is being interpreted by the SEO commentators in various articles, but we know how information gain is used explicitly in machine learning decision trees. One interpretation is subjective surmising, the other is an established reality.
Pinocchio explains more SEO and AI Search myths to Jiminy Cricket.
Yet another concept doing the rounds is LLMs.txt.
LLMs.txt, is touted as a means to herd AI bots in content discovery via the addition of a .txt file in a similar fashion to robots.txt, an Internet Engineering Task Force (IETF) protocol, originally established in 1994 by Martijn Koster, with its own RFC (Request for Comments) file in the IETF documentation.
LLMs.txt includes a summary of important content for tokenisation efficiency as well as robots.txt style allow and disallow instructions, and has also been proposed as a protocol too.
Sounds sensible right?
The problem is no major search engine (and barely any AI bots) recognise LLMs.txt as a viable protocol and strong evidence suggests this proposed new approach to SEO for AI search discoverability is moot at this time, with barely any AI bots fetching LLMs.txt files in tests by several SEO researchers.
However, many SEO tools and CMS providers are pushing ahead regardless, and adding to the myth-circulating nature of the SEO industry. Creating and adding an LLMs.txt file is already included as a recommendation for good organic search health in the SEO audit sections of some tools, without question, warning, or explanation.
Part of the reason why LLMs.txt’s popularity is growing is that there are actually some fairly sound arguments for its use, because crawling website content presents a big challenge for Generative IR and Generative AI systems. The vast majority of AI bots cannot render javascript, giving Google a distinct advantage when it comes to retrieving content from websites with client-side javascript. As such, providing a succinct summary of important content or tokens via LLMs.txt does have some merit. Furthermore, the ability to choose what content is fed to the AI bots, rather than allowing them to run wild and impact host load also makes sense.
To make matters more complicated, despite Google repeatedly claiming the protocol of LLMs.txt is not, and will not, be supported by them, several of their own developer sites suddenly appeared with LLMs.txt files. The LLMs.txt files disappeared from many of these platforms shortly afterwards, and Google has always maintained they do not give SEO advice to their own internal teams.
I feel like Google’s own developers believing they need to add LLMs.txt to their sites most clearly illustrates the power of the SEO myths which circulate.
What will become of LLMs.txt in the future is unknown. Maybe over time this proposed solution will be accepted as a recognised protocol, but I suspect there is more likelihood of AI bots succeeding in rendering and retrieving javascript content or learning where the most important chunks of data are throughout document collections via machine learning.
From my perspective, it’s too early to recommend that site owners add an LLMs.txt file as standard practice and feed into the dubious and ambiguous narratives driving the SEO space.

I vote for Pommies.txt Image credit: Marco Giordano
So where does that leave us?
Terms such as ‘chunking’ and ‘information gain’ are presented as new SEO levers, but these concepts (and others), are arguably not valuable as tactics beyond what was already there via semantic structuring and creating valuable content.
LLMs.txt is described by Google as being as useful as ‘SEO keywords’. That’s useless, right?
These terms are either hyped, misinterpreted, or bigger cross-domain concepts than they first appear.
In reality, good SEOs have always taken into consideration the ways in which search engines and natural language understanding systems handle content preprocessing; and recognise that much of their work is about disambiguation or ‘importance detection’ in a sea of unstructured content.
This is why I believe it’s important to continually pull the conversation back to the fundamentals beneath search, whether at its most basic level of IR, or fundamental workings of NLP tools of the era, (currently LLMs, and associated AI enablers).
When we do this, it quickly becomes clear that many of the so-called new GEO / AEO / EIEIO tactics currently in circulation, have actually been utilised within SEO strategies for years by those who appreciate that ontology, semi-structured and structured text, and tabular data is vital for IR disambiguation.
In a similar vein, many of the tactics around content structure should always have been in place and should be emphasised further, rather than continually distracting ourselves with quick, but temporary, underhand wins.
At the same time of course, we need to recognise that search is evolving, and there will understandably be a period of murkiness with new concepts to learn about.
So, above all else, clear thinking in the SEO space has never been more important. Follow the reference sections beyond the academic papers. Understand patents for what they are: often innovative and exciting ideas which aren’t actually implemented. Question and cross-reference advice from tool providers and influencers. Read widely and diversely across the industry, without bias or favouritism. Test for yourself. Embrace change objectively.
Search is complex. Think critically.
You can access all the recordings of the wonderful talks at WTSFest London 2026, for just £149!


Dawn Anderson - SEO Consultant and Founder, Bertey
For nearly 20 years, Dawn has focused on one core objective: helping some of the world’s largest brands achieve sustainable, measurable growth through data-led SEO and digital strategies.
Her work sits at the intersection of technical precision, content innovation, and creative strategy. She partners with enterprise-level organisations to solve complex search challenges, driving high-volume traffic and revenue in highly competitive markets - from Finance and Travel to Retail and Telecoms.