🌲 WTSFest Portland - May 2026 | 🥨 WTSFest Philadelphia - Oct 2026 | 🎥 On-Demand Video Hub - 2026
🌲 WTSFest Portland - May 2026 | 🥨 WTSFest Philadelphia - Oct 2026 | 🎥 On-Demand Video Hub - 2026

Author: Emina Demiri-Watson
Last updated: 23/06/2025

With AI Overviews increasingly dominating the SERPs and the wider roll-out of AI Mode on the horizon, many SEOs are seeing traffic drop and asking the big questions:
How does it actually work? And what can we do about it?
In this piece, we break down what we currently know about AI Overviews, drawing on:
We’ll start by unpacking key revelations from the DOJ trial exhibit, then zoom out to examine how generative AI, semantic search, retrieval-augmented generation (RAG), and user signals are fundamentally changing how content is retrieved and ranked.
Most importantly, we’ll look at what these developments mean for SEOs and digital marketers today.
Special thanks to Arnout Hellemans, whose insights into AI-powered search systems helped spark much of the exploration in this piece.
➡️ AI Overviews are powered by Google's proprietary generative system “MAGIT,” likely a fine-tuned Gemini model trained on real search queries for format-specific summarisation.
➡️ Retrieval-Augmented Generation (RAG) underpins the architecture, grounding AI responses with up-to-date information from Google's massive Search Index.
➡️ “Fast Search” infrastructure likely enables rapid retrieval at scale, possibly using techniques like caching to manage costs and latency.
➡️ Grounding sources may be selected after summary generation, meaning the AI response comes first, and links are added to validate it
➡️ Google’s use of “fraggles” (content fragments like passages or tables) aligns with how LLMs prioritise semantically rich, structured content.
➡️ User signals (clicks, dwell time, bounce rates) continue to influence visibility in AI Overviews. If your link gets ignored or abandoned, it may disappear.
➡️ Predictive summaries and query fan-out techniques expand beyond the original search query, surfacing implied and related intents, further reducing clicks to publisher sites.
➡️ AI Overviews contribute to major CTR drops. Studies show organic position 1 can lose up to 70% of its click-through rate when AIOs are present.
➡️ We don’t need to rebrand SEO as AEO, but if you’re not already deep into how LLMs, semantic search, and RAG work, it’s time to catch up. Start from the beginning, understanding how natural language processing works and only then move on to UX and content.
This exhibit, a piece of evidence formally presented to a court during a trial, includes the testimony of Prof. Gregory Durrett, an expert witness providing insights on Google’s use of search data, Generative AI, and related models.
His analysis is based on two primary tasks:

Source: Testimony of Prof. Gregory Durrett
Let’s break down the key insights revealed in Prof. Durrett’s work and how they impact our understanding of AI Overviews.
Google's AI Overviews are not a standalone technology. It’s a sophisticated amalgamation of advanced AI models, retrieval systems, and Google's foundational search infrastructure.
Here’s what we know from the expert testimony, much of this has of course been speculated on already, but now we have further confirmation
At the heart of AI Overviews lies a generator model reportedly codenamed "MAGIT"
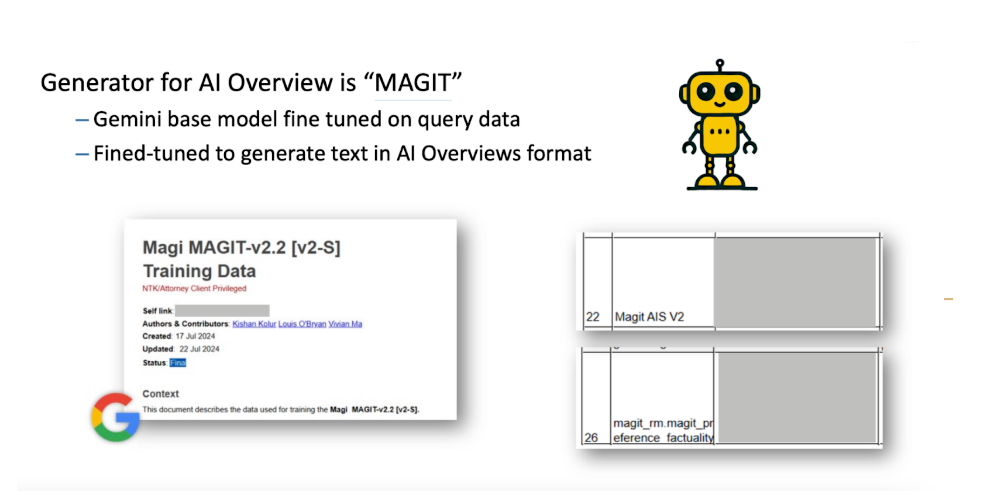
Source: Testimony of Prof. Gregory Durrett
This model seems to be a derivative of Google's Gemini base models. Just topped up with specific fine-tuning using query data.
Much has been redacted here. Presumably, this specialised training enables MAGIT to generate text in the distinct format and style characteristic of AI Overviews.
From the expert testimony, we also have confirmation that AI Overviews indeed use some type of RAG (Retrieval Augmented Generation) architecture.
As John Muller aptly said back in Zurich at Search Central: “We better get familiar and used to RAG.”
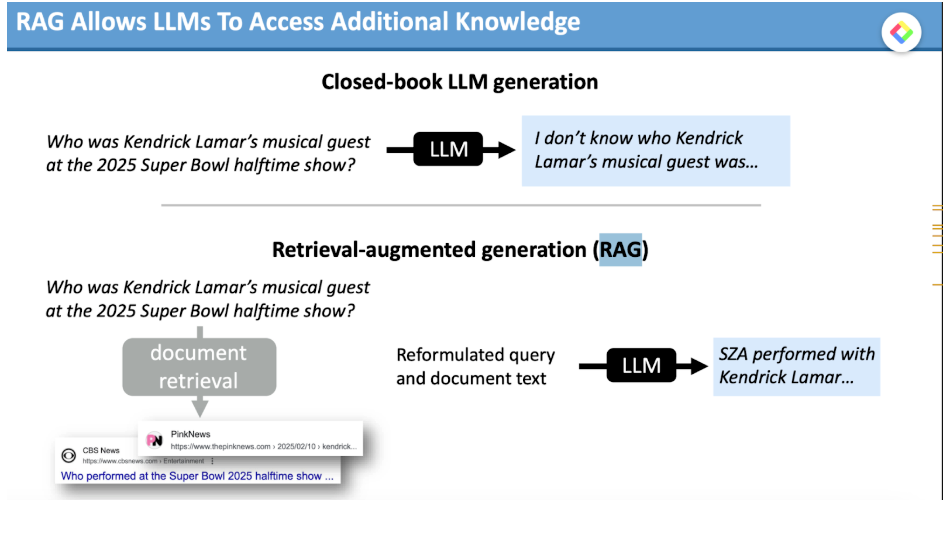
Source: Testimony of Prof. Gregory Durrett
RAG allows AI Overviews to access fresh, up-to-date information, overcoming the knowledge cut-off limitations. It also provides crucial factual grounding, which helps to reduce "hallucinations".
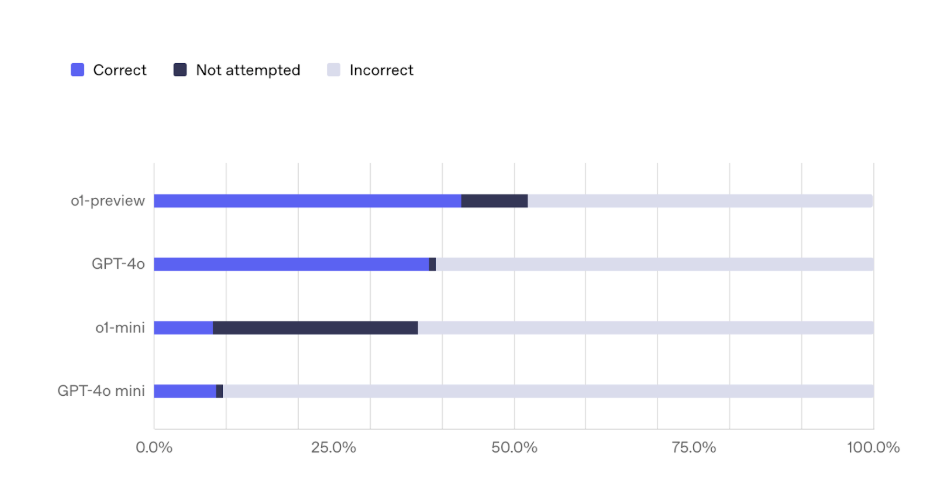
And, as seen by SimpleQA - a framework developed by OpenAI to evaluate the accuracy of LLM models - the hallucinations are rampant and grounding is very much needed.
Even the best-performing OpenAI o1 has an accuracy of only 42.7%
It’s important to understand that AI Overviews are not just an AI layer placed atop Google Search. And, this is something that clearly comes out of the Expert Testimony.
AI Overviews heavily relies on the existing Google Search stack, its massive Search Index, and already collected user-side data.
The Google Search Index, with its "hundreds of billions of webpages and is over 100,000,000 gigabytes" is THE knowledge repository for the RAG system powering AI Overviews.
Clues to how AI Overview accesses this information are in the details of the Expert Testimony.
Specifically, the mention of something called the "Fast Search" system.
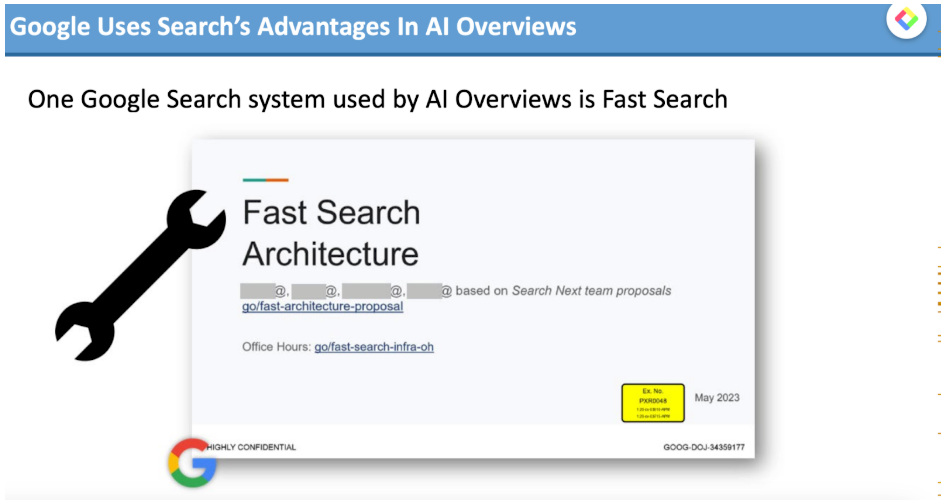
Source: Testimony of Prof. Gregory Durrett
Again, there are no specifics here, and elements have been redacted.
In general, we know that AI-powered search leverages machine learning (ML) and natural language processing (NLP) to go beyond simple keyword matching, instead understanding the meaning, context, and user intent behind each query.
In SEO we know this as semantic search; it’s been around for a while, ever since Google's Hummingbird update in 2013, and BERT in 2019,
We have moved long ago from keyword-based search to embedding-based retrieval, where both queries and documents are represented as dense vectors in a high-dimensional space. AI search results are the brainchild of this embedding approach, advanced algorithms, user behavioural data and personalisation (ie. location and beyond).
The existence of ‘Fast Search’, a proprietary infrastructure designed for rapid information retrieval and ranking, makes perfect sense considering the real-time generation demands of AI Overviews.
How it works, we don't really know.
But, recently Gemini API has had an interesting addition added to it, “implicit caching” which stores answers to FAQs.
Considering the high computing requirements and cost of real-time generation, I wouldn't be surprised if ‘Fast Search’ includes something similar.
There is also a question about how the grounding process actually works. Tom Critchlow suggests that LLMs (including AIO) “Write the answer, then find sources that sort of back it up.”
It seems plausible that conversational search operates across three levels - two of which are pretty much confirmed:
Another interesting element here is what we know about Google's use of ‘fraggles’.
Fraggles is a term coined by Cindy Krum and refers to Google's ability to index and rank specific fragments of content, like passages, lists, or tables, independently from the full page. Considering the cost and the computing power, retrieving relevant content fragments over entire pages for AI-generated responses makes a lot of sense.
Following this, query-document/fraggle semantic similarity might now actually be: query-AI Overviews response-fraggles/documents that support the response. The system might be looking for fraggles/documents from the index that are semantically closest to the AI Overview ready response AND the user’s query. Not just the query. The response was actually generated first -AI Overview is the primary content - and the sources were selected afterwards (Grounding links) to confirm it.
This would go slightly against the patent Generative summaries for search results, which makes a point of the generation process involving selecting relevant search results first, and then using content from these SRDs as input for the LLM to generate the summary. It does mention that in some cases the response is simply generated from training data, though.
Another interesting confirmation is yet again the use of user signals.
We know from earlier documentation from the trial, leaked data, and recent Google exploits that Google does use user signals. Chrome and likely Android as well.
And this is now, yet again, confirmed.

Source: Testimony of Prof. Gregory Durrett
There is a familiar system mentioned here: Google Glue.
An AI Overview occupies a single position in search results, and all links in the AI Overview are assigned that same position.
Presumingly, the order of the actual links within AI Overview or the loss of a position is therefore very much also a question of user signals.
In simple terms, if you feature in AI Overviews and no one is clicking on your result, you might not be there long.
If people are clicking on your result but then not spending any time on the page, you might also get bumped down or removed.
This has real implications on what we measure as SEOs - ie. measuring engagement data and thinking about keeping people on your site as long as possible has become even more important.
Clues to how Google determines these signals lie in understanding how search engines model and track user behaviour: users scan results top-down, evaluate snippet attractiveness, and click only if intrigued.
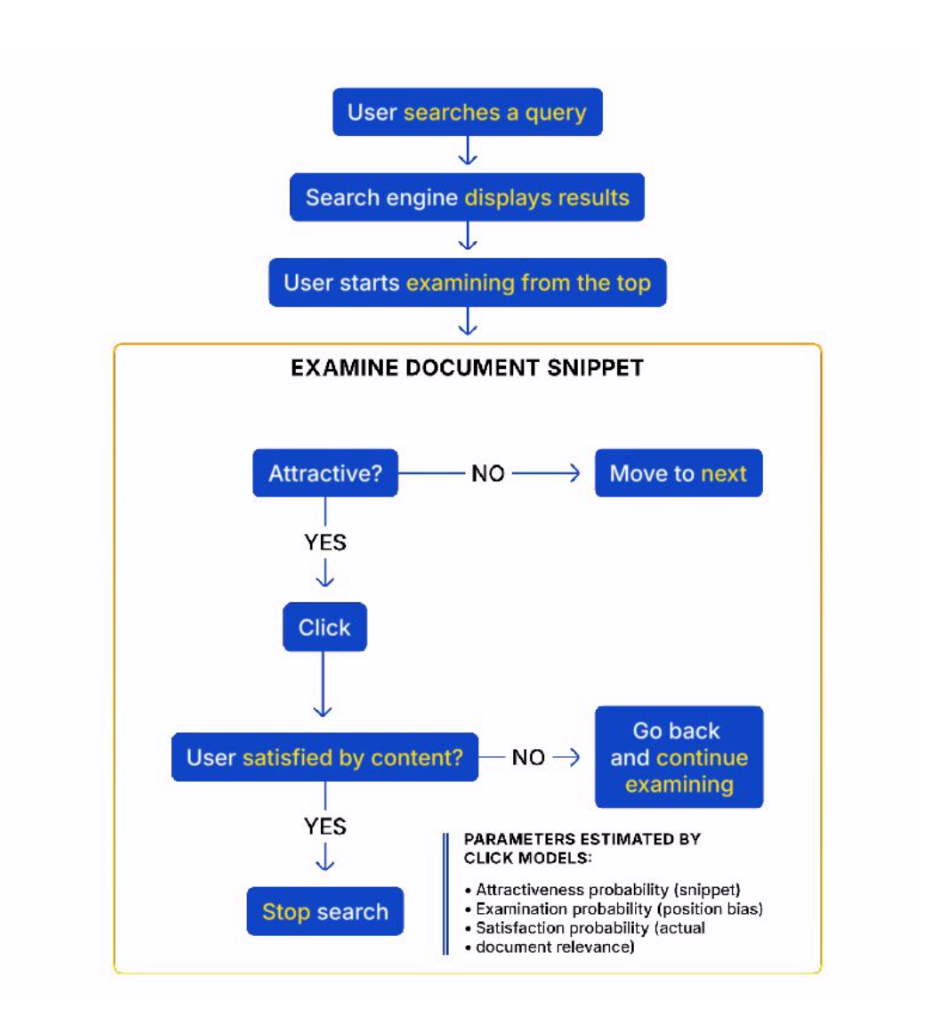
Source: The End of SEO as we know it, Mike King speaker deck
If content doesn't satisfy intent, they bounce back, feeding valuable engagement signals into machine learning systems like RankBrain and DeepRank. These logged interactions (clicks, scrolls, pauses, satisfaction) become proxies for “value judgments,” directly influencing rankings.
Looking at the Generative summaries for search results patent again, we can see how this is even more complex. User profile, device context, query history / co-occurrence all play a role in the summaries.
If you, for example, search for iPhone 15 reviews - the system might record an implied query "latest smartphone reviews" based on your user profile of someone interested in technology.
It also might develop a related query such as iPhone 15 camera review (because user data shows that this is usually the next step).
This means the summary would actually be constructed from all three of those - iPhone 15 reviews, latest smartphone reviews, & iPhone 15 camera review.
You search for iPhone 15 reviews, but you get a response that gets all three.

Source: SEO in 2025, Mike King, speakers deck
As Mike King explains in his recent speaker deck, it’s not just about what ranks for the query - it’s also about what ranks for ‘implied’ and ‘related queries’. Both of which are explicitly mentioned in the patent!
Recently, Danny Sulivan also shared some useful insights into the inner workings of AI Overviews and the now imminent AI Mode.
Specifically, he mentions several key mechanisms:
Predictive summaries:
Rather than simply relying on the top 10 organic search results, the AI model takes a broader approach, analysing a wide range of information to predict user interests, potential follow-up questions, and related topics.
This explains why sometimes those websites on page 1 in traditional search results are not the same as those mentioned in AI Overviews.
Grounding links:
To make those summaries more robust and trustworthy, Google uses "grounding links" — hyper-specific, contextually relevant sources that directly support the information presented.
Query fan-out technique (experimental AI Mode):
Personally, this is the one that I find most interesting.
In essence, AI Mode seeks to go a step beyond in its understanding and predictability of intent. The user’s query is not processed as a single request.
Instead, it generates multiple related queries to understand the full context of the user's search intent, exploring different aspects of the topic even further.
And, as a result, potentially keeping even more users on the Google results page, instead of sending traffic to publishers.
Sounds familiar? That’s because it’s closely connected to the idea of generating results not just for the query, but also for implied and related queries.
While digging into the expert testimony, I couldn't stop myself from consulting Gemini as well.
After all, not using LLMs to support your research these days is madness. As long as you use LLMs responsibly!
The research it gave me was actually quite useful, but I was particularly impressed with the table. Sharing it here in hopes it helps you as well, unpack the systems at least a bit.
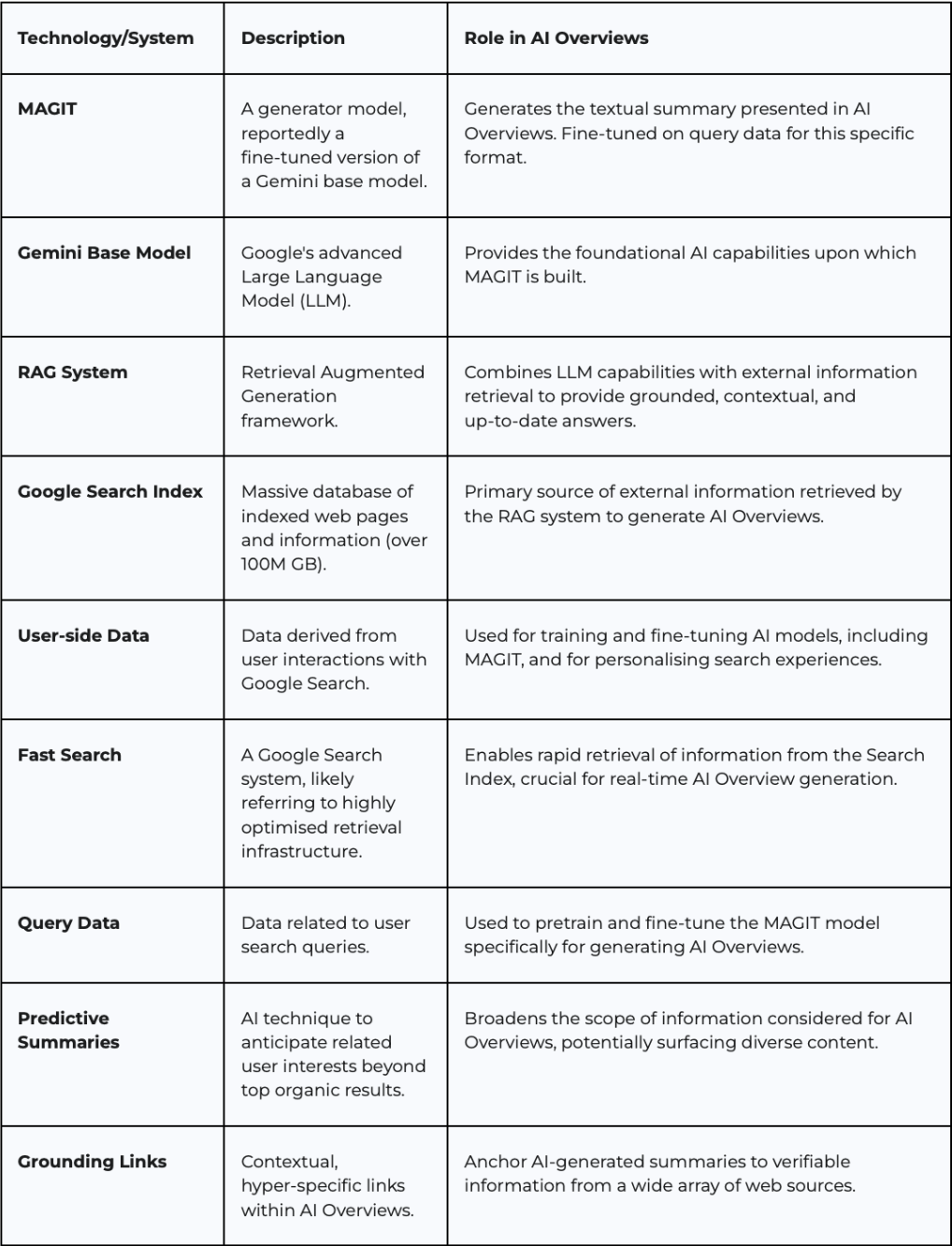
Table comparing different systems
AI Overviews represent a fundamental change in the concept of "search”. As Google puts it - it takes the work out of search.
Image source: Google Search Help
The issue is that the result of that work has historically been traffic. And, the traffic is going down!
According to Ahrefs, websites are experiencing a whopping 34.5% drop in position 1 CTR when AI Overviews were present, based on an analysis of 300,000 keywords.
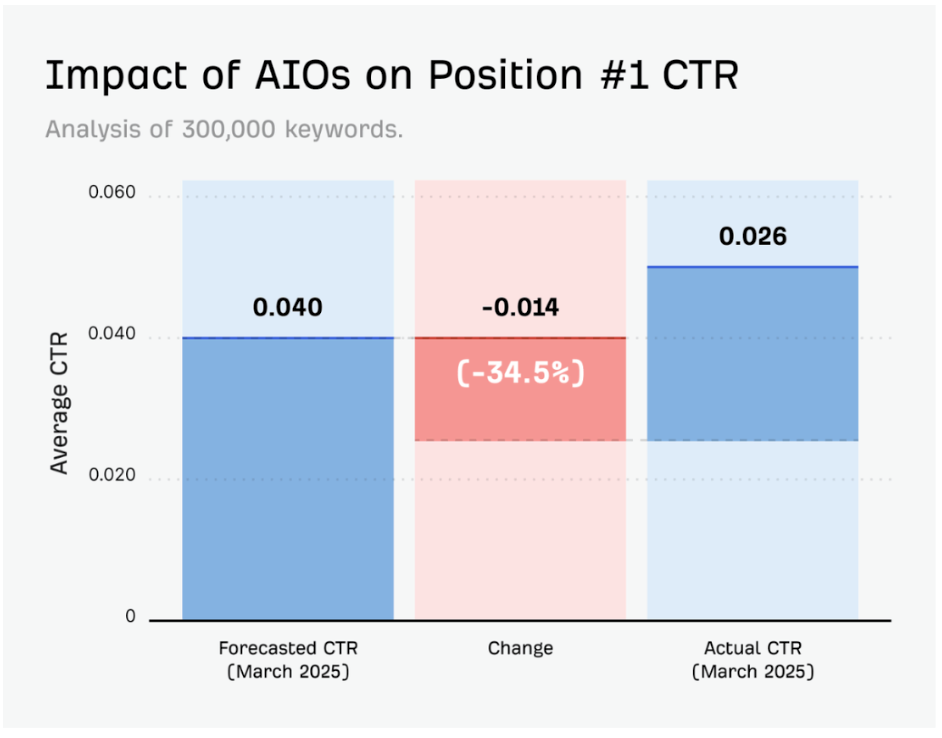
Image Source: Ahrefs
Seer Interactive research shows us an even grimmer reality, with Organic CTR declining 70% when an AIO was present on the SERP.

Image Source: Seer Interactive
This is further supported by a recent UX study done by Kevin Indig, which highlights that user interactions are shifting significantly, with fewer users clicking through to websites.
Even though the study confirms Google’s claim that AIOs may act as a "jumping-off point," they are just as effective at killing clicks, especially for informational queries.
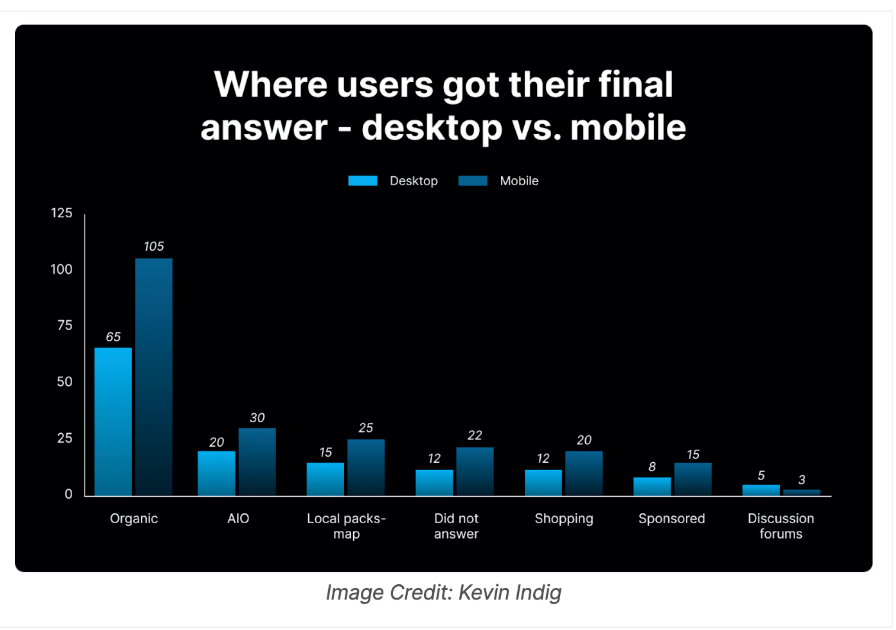
As SEOs, in the business of search, understanding this shift is of massive importance.
As AI Overview and AI Mode become the main ways users interact with search, both we as SEOs and the wider content publishing community need to pay close attention.
For many, Google has been for too long the bread and butter and caring about this shift and what we can learn about the inner workings of AI-powered search is a no-brainer.
As AI-driven search continues to gain ground and traffic dwindles, SEO’s are wondering if they should be changing their strategies and how.
Is traditional SEO enough, or do we need a rebrand to AEO?
As Kevin Indig recently wrote, Answer Engine Optimisation is the same, same but different from traditional SEO.
We don’t need a new acronym, partly because things are changing so fast that any exact strategies are impossible to set at this point.
We do know that the core tenets of traditional SEO - brand, links, creating valuable, authoritative, and technically sound content - remain the same.
Alongside this, for now, a safe bet is to focus on three general areas:
Google has long moved from lexical to semantic search, and yet many SEOs are still confused about what is actually meant by this.
Many of us are still stuck on the keyword matching, not the meaning matching.
I agree with Mike King when he says this is partly due to the SEO tech stack being slow in making the switch.
With the dominance of LLM re-ranked search and rise in zero-click searches, SEO and the tools we use will need to finally understand how search engines and LLMs actually ‘read’ our content.
My advice is to start from the beginning, understanding how natural language processing works.
Two foundational resources that can help are:
To help understanding, I also suggest using Notebook LLM. Neither of the two is for the faint-hearted, but they are well worth the time and effort.
Explore your analytics and understand what users are doing on your website. What journeys are they taking and why? Talk to your customers and understand what they are looking for. Map out those journeys and improve the UX at least a bit. Or ideally, connect to your UX team and get them to help!
Use tools like heatmaps, session replays, and behaviour flow visualisations to get a clearer picture of how users actually move through your site. Monitor user interaction metrics (CTR, dwell time, bounce rate) closely and explore the different journeys users take, not just where they land, but how they navigate, where they hesitate, and where they drop off.
Your content needs to not only attract clicks but also satisfy users’ needs immediately.
Strategies such as designing navigation that serves users on a website and article level, testing using different formats (video, infographics, interactive explainers) to increase engagement and reducing friction in critical paths can directly influence satisfaction signals.
A useful framework to think about optimising your website, content and in general, anything for people is the frame it as ‘reducing cognitive load’.
As Arnout Hellemans puts it:
‘Whether it's a supermarket shelf or a DJ set layout or a website checkout....It’s our task to lower the cognitive load. ‘
One of the best pieces I’ve read on this topic is the recent article by Carolyn Shelby on How LLMs Interpret Content.
She outlines some key takeaways, which personally sound extremely sensible.
If you are not already doing this as part of your traditional SEO workflows, you'd better start:
Watch your structure. LLMS prioritise well-structured content. Clear formatting, logical hierarchy, and organised information help LLMs interpret and retrieve content more effectively. This also aligns with what we know about the use of ‘fraggles’ in LLM responses.
Another great resource is Francine Monahan's piece on Relevance Engineering. The semantic suggestions for improving content relevance closely align with Carolyn Shelby’s recommendations, but add a deeper technical layer for those looking to explore further. In particular, using explicit semantic triples or clear subject–predicate–object patterns as a way to significantly boost retrieval accuracy and content relevance.
The other side of this coin is the originality piece. How can we ensure our content provides information gain, a unique and original POV or information piece that helps us stand out and rank? A great framework for thinking of this is: I.N.S.I.G.H.T, created by Dorron Shapow .
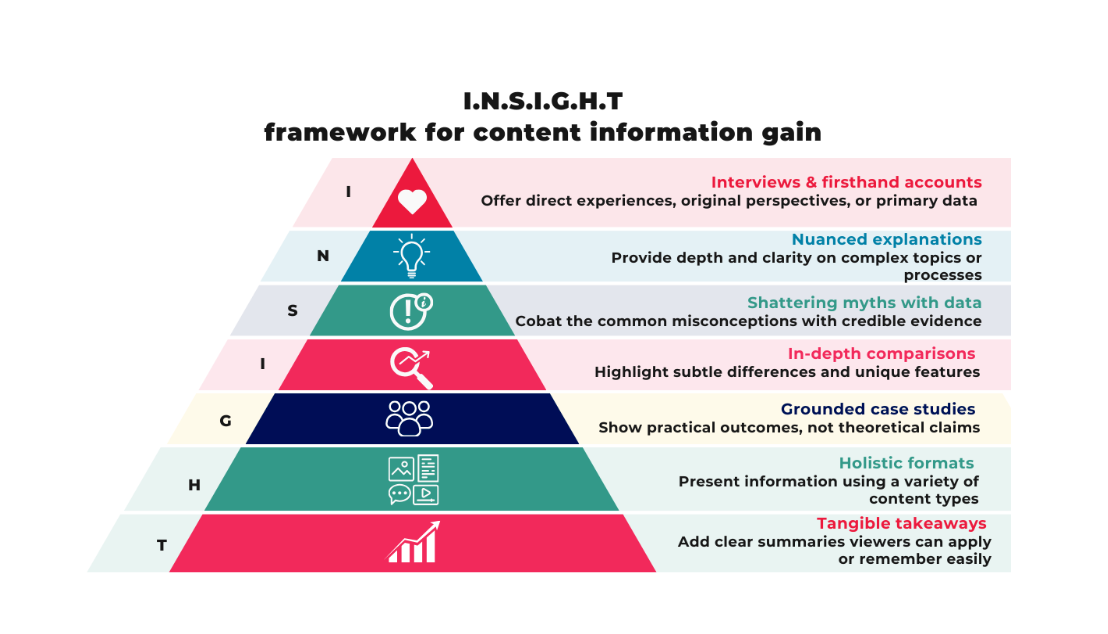
With AI content being rampant and polluting the digital ecosystem, being authentic and adding information gain is a competitive advantage.
To put it simply: your content needs to add to the discussion, not simply regurgitate the same information, in the same format as others.

Emina Demiri-Watson - Head of Digital Marketing, Vixen Digital
Emina has over 10 years of digital marketing experience both in-house and agency side. She is the Head of Digital Marketing at a Brighton-based digital marketing agency Vixen Digital, and co-hosts the SEO Getting Coffee podcast.
We pay our authors, speakers & team to bring you helpful content like this.
We aim to always keep our content and community free and accessible.
If you've found value in WTS, please consider supporting us through our Buy Me a Coffee initiative.
